SpringCloud笔记 (Netflix)

微服务与SpringCloud
为了降低大型WEB应用复杂性,以及应对越来越高的并发要求,微服务出现了(大嘘)。
可以简单理解为,就是将一个大的应用,拆分成多个小的模块,每个模块都有自己的功能和职责,模块之间可以进行交互。
SpringCloud是一套微服务解决方案,包含数个组件,而这些组件或者说SpringCloud的方案最早来自于Netflix(就是你看不到的那个网飞),而现如今Netflix很多组件已经不再开源更新,就有了SpringCloudAlibaba这种新方案,有不同的组件搭配。
常见的组件有:
| 服务的注册和发现 | Eureka, Nacos, consul |
| 服务的负载均衡 | Ribbon, Dubbo |
| 服务的相互调用 | OpenFeign, Dubbo |
| 服务的容错 | Hystrix, Sentinel |
| 服务网关 | SpringCloud Gateway, Zuul |
| 服务配置的统一管理 | Config-server, Nacos, Apollo |
| 服务消息总线 | Bus |
| 服务安全组件 | Spring Security, Oauth2.0 |
而常见的实现方案有:
1 | |
目前完成了SpringCloud Netflix的部分,并将某些组件更换为更现代化的,如网关使用Gateway和更新的OpenFeign。SpringCloud Alibaba正在路上,待我用目前的组件完成毕设再来写。
Netflix Eureka
Eureka作为服务注册与发现的组件和其他Netflix公司的服务组件一起,被Spring Cloud社区整合为Spring Cloud Netflix模块。
Eureka不再开源更新!所以采用SpringCloud Netflix并不是一个好的选择!
CAP 定理
指的是在一个分布式系统中:
1 | |
这三个要素最多只能同时实现两点,不可能三者兼顾,而分区容错性必须存在——即CP/AP二选一,Eureka为AP。
依赖
创建SpringCloud项目仍然使用Spring Initializr。
Eureka服务器只需要添加Eureka Server,Eureka客户端则需要Eureka Discovery Client。
SpringCloud某个版本往往只能使用某几个版本的SpringBoot和各种组件,但你通常无需在意。
服务端
在启动类前添加注解@EnableEurekaServer才会启用Eureka服务器,这时候只要启动这个SpringBoot项目就会运行起来EurekaServer。(这个服务端抱着SpringBoot大腿跑,不用另外配置部署)
在SpringBoot的配置文件中,你至少需要配置:
1 | |
这个时候浏览器访问http://localhost:8761就可以进入Eureka的信息网页。
Eureka服务端既是一个提供注册功能的服务端,也可以作为客户端注册到别的Eureka服务端,默认开启并会自己注册自己,后面将利用这个功能形成Eureka集群。
服务端常用额外配置:
1 | |
客户端
在启动类前添加注解@EnableDiscoveryClient才会启动Eureka客户端,老版本为@EnableEurekaClient,建议使用前者。
类似地至少需要配置:
1 | |
常用额外配置:
1 | |
客户端定期向注册中心发送心跳证明自己存活,也获取一份服务列表以便于调用其他服务。
集群
要建立Eureka集群,需要将Eureka服务器放在不同的机器上,然后在任一服务器节点的配置文件eureka.client.service-url中添加其他所有节点,形成一个两两连接的网络。
配置如下:
1 | |
在单一机器上改变端口配合hosts文件修改也可以实现,但是这没有多大意义
客户端,则在eureka.client.service-url中添加所有节点。
Eureka集群没有主机和从机的概念,节点都是对等的,集群中的服务端会交换服务列表,且只有集群里面有一个节点存活,就能保证服务的可用性。
Docker部署
需要在SpringBoot配置文件中,把可能需要改变的参数写成EL表达式,像:
1 | |
要注入变量,只需要运行Docker时添加-e PORT=11451。
Netflix Ribbon
Ribbon 是一个基于 HTTP 和 TCP 的客户端负载均衡工具,Ribbon可以和RestTemplate结合使用,RestTemplate类似于OkHttp之类的Http请求库,但更常用的是和OpenFeign一起使用并且被OpenFeign集成,故Ribbon可以不怎么看。
通过RestTemplate使用Ribbon,只需要引入Ribbon,然后在创建RestTemplate的Bean方发出加上@LoadBanlanced,如下:
1 | |
然后在需要调用其他服务的地方注入,然后访问http://服务名称//....即可,因为Ribbon已经通过注册中心拿到了服务列表,因此你只需要给服务名称。
服务名称就是 spring.application.name
OpenFeign (Netflix Feign Plus)
Feign 是声明性(注解)Web 服务客户端,个人理解就是通过注册中心自己找服务简化Http调用。
Feign是Netflix公司的且不在开源更新,而OpenFeign是SpringCloud搞出来的,在Feign的基础上支持了SpringMVC的注解等各种改进,现在说到Feign通常都是OpenFeign。
服务提供者(被调用者)
被调用者不需要什么额外的依赖,什么也不需要改动,只需要保证自己在注册中心注册了,并且有Web接口即可。
服务使用者(调用者)
需要引入OpenFeign依赖(当然也需要注册中心),Spring Initializr里面就有。
然后在启动类上启用Feign客户端,添加注解@EnableFeignClients。
并且创建接口(建议放到feign包),添加@FeignClient注解,其value为服务处提供者的服务名称。
最后,将服务提供者Web接口的签名复制粘贴,如下:
1 | |
调用只需要:
1 | |
库底层通过为接口创建代理类实现,类似于装饰器之类的设计模式。
参数传递
在Feign中想要传递参数,接口的@PathVariable、@RequestParam、@RequestBody等都不能省略,建议控制器本身和Feign接口均不省略且保持一致(包括require等参数)(这应该是规范一部分)。
通过Feign远程调用传递时间参数时,如Date对象,可能遇到时区不一致问题,可能直接换算时区过来也不正确,会出错是因为旧版本OpenFeign还在使用new Date(date.toString())这种有问题的方法,新版本POST请求@RequestBody传Date对象实测没有问题,如果你还在使用旧版本可以考虑:
- 将传递Date对象变为传递序列化后的字符串,接收方再反序列化。
- 使用JDK8的LocalDate(日期)或LocalDateTime(精度到秒的日期)对象。
- 魔改Feign。
更换连接组件
OpenFeign或者说Ribbon默认使用HttpURLConnection实现,如果传参有Body则会强制转为Post,这将导致MethodNotAllowed,要解决可以选择放弃传递Body的Get请求或使用其他请求组件。
但使用其他请求会遇到很多问题配置可能比较复杂,这里不记录我自己也不用,等到遇到性能瓶颈不得不改时会更新这个部分。
超时
如果通过Feign调用服务,被调用方长时间处理,可能会导致超时,进而调用方向用户报500错误。
因为OpenFeign底层使用Ribbon,因此调节超时时间应该通过Ribbon配置调节:
1 | |
日志
Feign 提供了日志打印功能,我们可以通过配置来调整日志级别。
开启日志,需要通过配置类配置日志打印级别:
1 | |
然后对你的Feign接口启用debug级别日志:
1 | |
Netflix Hystrix
服务雪崩
1 | |
如上所示的链式服务调用(依赖)中,服务提供者C因为某种原因出现故障,那么服务调用者服务B依赖于服务C的请求便无法成功调用其提供的接口,依赖于服务C的请求越来越多导致服务B的服务器或Web容器资源耗尽,造成服务B线程阻塞,导致服务B也出现故障。紧接着,服务A依赖于服务B,由于服务B也出现了故障导致服务A出现故障。以此类推引起整个链路中的所有微服务都不可用。
通常的解决办法有:
- 超时处理:设定超时时间,请求超过一定时间没有响应就返回错误信息,不会无休止等待
- 线程隔离:限定每个业务能使用的线程数,避免耗尽整个Web容器的资源,因此也叫线程隔离。
- 熔断降级:由断路器统计业务执行的异常比例,如果超出阈值则会熔断该业务,拦截访问该业务的一切请求。
- 流量控制:制业务访问的QPS,避免服务因流量的突增而故障。
在分布式链路中,只要有一个服务不可用,都会导致整个业务或者链路瘫痪!
服务雪崩的本质是线程没有及时回收。
Hystrix是一个熔断器、断路器,保护服务不产生服务雪崩。
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。
使用Hystrix
Hystrix常与OpenFeign、Ribbon一起使用,因为有服务调用才会有服务雪崩的发生,Hystrix才能隔离服务的访问点阻止联动故障。
服务提供者依旧无需改动,除非他也要调用其他服务。
添加Hystrix依赖:
1 | |
你可能需要去掉version,也可能需要version,在我这(阿里镜像)不加version无法添加依赖。
某些版本的SpringCloud,可在Initializr里的SpringCloud CircuitBreaker下找到Hystrix,但我的3.0版本只有一个Resilience4J。
然后,在配置文件中开启:
1 | |
实测新版本没有了这个配置,也不在spring.cloud.openfeign下。翻阅其他文档得知,是在启动类上添加@EnableCircuitBreaker注解,也可以尝试用@SpringCloudApplication和@EnableHystrix。
在网上搜索文档的时候看到很多使用@HystrixCommand注解并配合RestTemplate使用的文章,但我看的文档使用OpenFeign时写法并不相同,但流程大同小异,因此想看的自行搜索。
要提供熔断机制,或者说熔断后的降级、替代措施,需要一个实现Feign接口的实现类:
1 | |
这时候@Autowired注入OrderServiceFeign时,会有冲突,因为存在Feign的代理类和上面这个类,你可以使用@Resource或者添加@Qualified
同时,在原Feign接口的@FeignClient中添加fallback类,指定为我们实现的类:
1 | |
原理
Hystrix本质类似于AOP切入了服务调用请求的过程,在开始前判断断路器开关,在结束后判断是否要更新断路器状态,相当于用了@Around。而断路器是决定调用请求进Fallback还是正常访问一个拦截机制。
断路器状态通常有关,开,半开。当为关是不拦截服务调用;当一定时间内调用失败次数达到阈值断路器将会打开,请求将进入Fallback(熔断了);当断路器打开是会让少许请求尝试调用服务,如果成功那么断路器将关闭,此时业务恢复正常。
Sleuth
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的服务节点调用来协同产生最后的请求结果,每一个请求都会开成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引导起整个请求最后的失败。因此我们需要一些链路跟踪监控工具来监控我们的微服务,链路追踪指的是追踪微服务的调用路径。
不建议微服务中链路调用超过3次。
Sleuth是Spring Cloud提供的分布式系统服务链追踪组件,它大量借用了Google的Dapper,Twitter的Zipkin。
通常的方案是Sleuth+Zipkin,Zipkin 是 Twitter 的一个开源项目,允许开发者收集 Twitter 各个服务上的监控数据,并提供查询接口。该系统让开发者可通过一个 Web 前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
Sleuth是一个上报工具,而Zipkin是一个处理和展示Sleuth所上报信息的工具。
运行Zipkin
根据仓库Readme中的提示下载运行Jar即可。
默认在本地的9411端口启动,用浏览器可以进入。
Zipkin中有一些关键概念:
Trace:Zipkin使用Trace结构表示对一次请求的跟踪,一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系,Trace就是树结构的Span集合。
Span:每个服务的处理跟踪是一个Span,可以理解为一个基本的工作单元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等。
整合Sleuth
除了注册中心之类的东西,都需要添加Sleuth进行上报,添加依赖:
1 | |
有配置:
1 | |
Admin
Spring Boot Admin 用于监控基于 Spring Boot 的应用,它是在 Spring Boot Actuator 的基础上提供简洁的可视化 WEB UI。Spring Boot Admin 提供了很多功能,如显示 name、id 和 version,显示在线状态,Loggers 的日志级别管理,Threads 线程管理,Environment 管理等。
在 Spring Boot 项目中,Spring Boot Admin 作为 Server 端,其他的要被监控的应用作为 Client 端。
监控Admin/Server端
添加依赖:
1 | |
启动类需要添加注解@EnableAdminServer。
并配置注册Eureka和安全相关:
1 | |
被监控Client端
需要引入依赖:
1 | |
通过Actuator暴露服务的健康数据等(实际上是一堆/actuator开头的接口)。
默认只暴露少量健康信息,想要更多信息(详细到Beans),需要配置:
1 | |
其实我觉得没必要整这个东西,只需要加个Actuator依赖配置下暴露的内容,用IDEA自带的调试看看就够了。
Gateway
SpringCloud Gateway是Spring官方用来取代Netflix Zuul的新网关组件,通过它和注册中心我们可以负载均衡地访问各个服务,无需知道服务具体的端口。如果你了解过NGINX,那么可以看做它的阉割版。
举个例子,通过访问80端口网关的/provider-a/abc/method?value=...通过配置可以转发到位于6666端口的服务上调用/abc/method?value=...,而前端无需知道服务在6666端口上。
Gateway的工作流程类似Tomcat等Web容器,客户端发出请求,然后在 Gateway Handler Mapping 中找到与请求相匹配的路由,将其发送到 Gateway Web Handler,其再通过一系列指定的过滤器(PRE过滤器)来将请求发送到我们实际的服务的业务逻辑,然后返回,会再经过过滤器链(POST过滤器)回到用户手里。
Gateway是运行在Netty上基于Webflux构建的,但使用起来没有什么差别。
核心概念
| Route 路由 | 包含ID、目标URI、断言和过滤,相当于一条反向代理设置 |
| Predicate 断言 | 通过请求中各种信息决定是否可以走这条路由 |
| Filter 过滤 | 对请求和响应进行处理 |
建立网关
SpringCloud Gateway就像Eureka,引入依赖启动就是一个网关。
通常需要引入Gateway本身和注册中心客户端,注册中心客户端用于拿到其他服务进行动态路由。你可以通过Spring Initializr添加Gateway和Eureka Discovery Client或者手动添加:
1 | |
使用Eureka客户端,当然需要在启动类前添加@EnableDiscoveryClient。
添加了Gateway依赖就会自动配置启用,但我们需要配置其他一些东西:
1 | |
配置路由
我们可以使用动态路由或静态路由,动态路由通过注册中心拿到具体的服务地址并有负载均衡,而静态路由只是简单地帮你转发到一个固定的地址上,通常项目中都是使用动态路由。
静态路由
这是一个配置静态路由的例子:
1 | |
有时候我们想实现通过访问gateway的/a/doApi来调用目标的/doApi,而没有前面的/a/,这需要过滤器StripPrefix:
1 | |
断言和过滤器非常多,具体可以看文档查阅。
动态路由
动态路由只需要在自身已经注册到注册中心的情况下,开启即可:
1 | |
然后就可以通过.../服务名称/method?value....的方式访问各个服务,并有负载均衡。
但如果你想像静态路由那样给个自定义路径名称,那就需要:
1 | |
此时访问gateway的/service/doApi就相当于访问service-name服务的/service/doApi。
注意URI的协议为lb(LoadBalance),表示启用Gateway的负载均衡功能,网关将类似使用Ribbon那样自动将服务名称转换为地址。
使用动态路由时,你实现GloabalFileter时exchange.getRequest().getPath()将会得到带有服务名称前缀的请求路径!如:/service-xxx/api/method
跨域
现在不用在Boot项目的每个控制器前加@CrossOrigin这种东西了,只需要对网关进行配置。
可以在配置文件中添加:
1 | |
上面配置应该和下面这种配置类方式一致:
1 | |
以上是简单的全局跨域,作用于网关下所有微服务,可能会影响到应用的其它部分。如果需要更细粒度的控制,可以使用路由规则级别的配置方法。
添加一个跨域过滤器:
1 | |
像这样作用于某个路由规则:
1 | |
也可以使用自定义但没必要:
1 | |
断言工厂简单了解
这里说的断言其实是Java的Lambda中的一种“预设”,你应该早就见过了诸如Consumer、Supplier之类的,而Predicate就是接受参数返回boolean的一个断言/判断函数,就像boolean isValueOk(Object inValue)。
通俗的说,断言就是一些布尔表达式,满足条件的返回 true,不满足的返回 false。Spring Cloud Gateway将路由作为Spring WebFlux HandlerMapping基础架构的一部分进行匹配。所有这些断言都与HTTP请求的不同属性匹配。
这些断言的作用如下图所示:
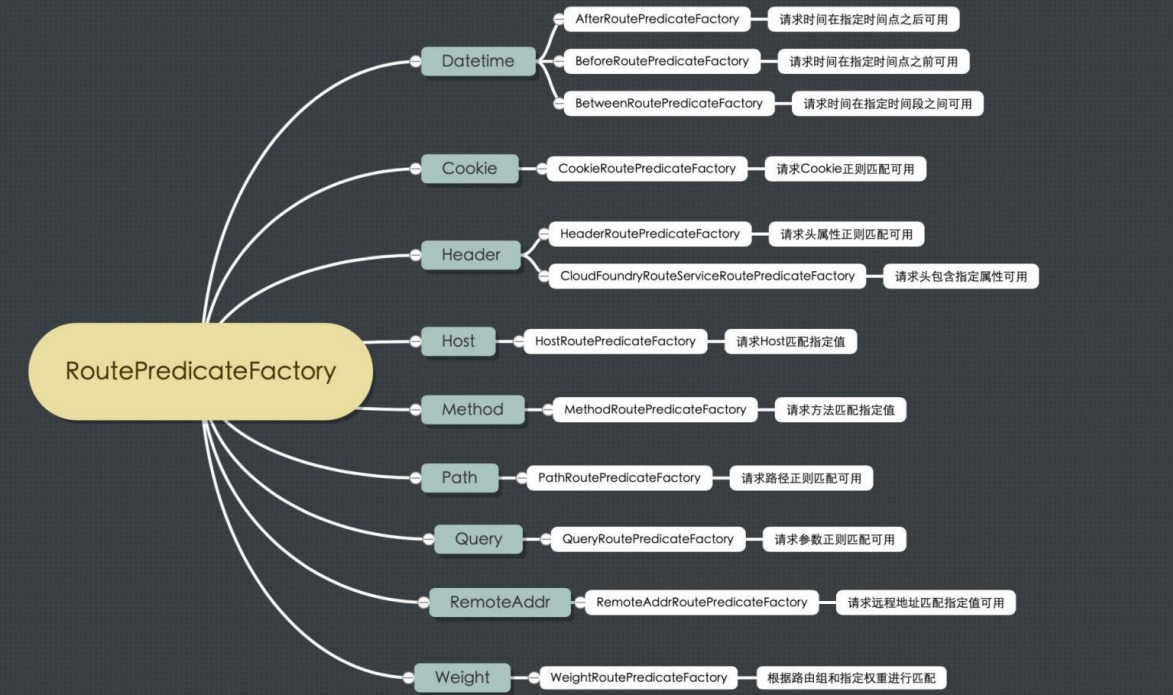
一些使用的例子:
1 | |
断言也可以自定义,但是自带的已经足够,通常没人去自定义。
过滤器工厂简单了解
过滤器分为针对某一条路由的GatewayFilter和作用于所有路由的GlobalFilter,并且这些过滤器的作用与之前用过的Web容器或者说Servlet中的基本一致,如果你还记得如何用拦截器实现登录验证功能那你应该不会有什么疑问。
与断言不同的是,过滤器通常是我们自己自定义实现的,用来实现登录之类的功能。
一个全局拦截是否有token的例子
1 | |
一个限流过滤器例子
限制一段时间内,用户访问资源的次数,减轻服务器压力,有对用户IP进行访问次数限制和一段时间内对接口请求次数的限制。
以通过令牌桶算法与Redis为例实现。
首先我们需要在使用Gateway的基础上引入Redis的依赖>spring-boot-starter-data-redis-reactive,然后在配置文件中连接Redis并配置过滤器:
1 | |
创建配置类,包含上文的限流解析器:
1 | |
SpringCloud工程项目布局
SpringCloud项目通常是一个Maven父模块带着几个SpringBoot子模块,而父模块一般继承SpringBoot爷爷模块。
以IDEA为例,个人习惯是用Spring Initializr先创建一个SpringBoot项目,并且顺便勾选Cloud的依赖(比如Eureka),然后用Spring Initializr创建子模块,修改pom中的父模块指向。
将得到父模块的pom中将有:
1 | |
使用Spring Initializr创建的pom还会有build块,需要删掉,因为父模块不需要编译!
子模块的pom:
1 | |
因为使用Spring Initializr不能指定父模块,所以你需要自己注意所有子模块和父模块都应该在一个组下。
而子模块之间可以抽离出一些公用的东西,比如将所有实体类、DAO层、Redis操作等都抽离出来放到类似service-common的子模块中,这在使用MybatisPlus并配合MybatisX插件生成DAO层和CRUD服务层时非常方便。
此时只要其他模块在dependencies中添加你的common模块,并在使用common模块的模块都配置好数据库和Redis连接地址即可。(最好把common模块里的配置文件删掉)
据说还可以通过配置中心或者配置文件包含之类的方式统一设置,笔者对此并不了解且可能会引发问题,后面可能会更新。另外,上述做法还能让不同模块用不同的数据源。
- 标题: SpringCloud笔记 (Netflix)
- 作者: Sodacooky
- 创建于 : 2023-01-14 11:45:14
- 更新于 : 2026-03-14 17:17:08
- 链接: https://sodacooky.github.io/2023/SpringCloud/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。